前言
An unbounded {*@link *java.util.concurrent.TransferQueue} based on linked nodes.This queue orders elements FIFO (first-in-first-out) with respect to any given producer.
LinkedTransferQueue基于链表实现于TransferQueue接口,是一个遵循FIFO的队列。TransferQueue具有阻塞队列的行为(继承BlockingQueue接口),并且producer也可以阻塞等待consumer从队列中取出该element消费。
源码分析自 JDK 1.8.0_171
1 | public interface TransferQueue<E> extends BlockingQueue<E> { |
LinkedTransferQueue除了有BlockingQueue的行为外,还具有以上行为。
概述
LinkedTransferQueue实现了TransferQueue接口,而TransferQueue又继承自BlockingQueue。
众所周知,阻塞队列是生产者往队列放入元素,消费者往队列取出元素进行消费,如果队列无空闲空间/无可用元素则生产者/消费者会相应阻塞。
一般的阻塞队列,生产者和消费者是互不关心的,即两者完全解耦。正常情况下一般是不会互相阻塞(队列有足够的空间,生产者不会因为队列无空闲空间而阻塞;队列有足够的元素,消费者不会因为队列无元素可取而阻塞)。生产者将元素入队就可以离开了,不关心谁取走了它的元素;消费者将元素取出就可以离开了,不关心谁放的这个元素。但是TransferQueue不是,它的生产者和消费者允许互相阻塞。
LinkedTransferQueue的算法采用的是一种Dual Queue的变种,Dual Queues with Slack。
Dual Queue不仅能存放数据节点,还能存放请求节点。一个数据节点想要入队,这个时候队列里正好有请求节点,此时”匹配”,并移除该请求节点。Blocking Dual Queue入队一个未匹配的请求节点时,会阻塞直到匹配节点入队。Dual Synchronous Queue在Blocking Dual Queue基础上,还会在一个未匹配的数据节点入队时也会阻塞。而Dual Transfer Queue支持以上任何一种模式,具体是哪一种取决于调用者,也就是有不同的api支持。
FIFO Dual Queue使用的是名叫M&S的一种lock-free算法(http://www.cs.rochester.edu/u/scott/papers/1996_PODC_queues.pdf)的变种。
M&S算法维护一个”head”指针和一个”tail”指针。head指向一个匹配节点M,M指向第一个未匹配节点(如果未空则指向null),tail指向未匹配节点。如下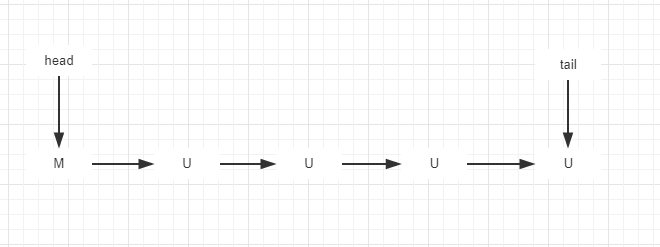
在Dual Queue内部,由链表组成,对于每个链表节点维护一个match status。在LinkedTransferQueue中为item。对于一个data节点,匹配过程体现在item上就是:non-null -> null,反过来,对于一个request节点,匹配过程就是:null->non null。Dual Queue的这个match status一经改变,就不会再变更它了。也就是说这个item cas操作过后就不会动了。
基于此,现在的Dual Queue的组成可能就是在一个分割线前全是M节点,分割线后全是U节点。假设我们不关心时间和空间,入队和出队的过程就是遍历这个链表找到第一个U和最后一个U,这样我们就不会有cas竞争的问题了。
基于以上的分析,我们就可以有一个这样的tradeoff来减少head tail的cas竞争。如下: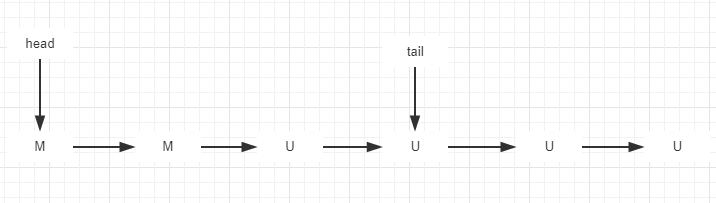
将head和第一个未匹配的节点U之间的距离叫做”slack”,根据一些经验和实验数据发现,slack在1-3之间时工作的更好,所以,LinkedTransferQueue将其定为2。
源码阅读
关于BlockingQueue的相关行为不做过多解读,主要看继承自TransferQueue的行为。
内部变量
1 | /** |
由以上代码能看到,内部维护的变量相对来说还是比较少的,主要是链表的head 和tail。最下边的四个静态场景是作为xfer方法how参数,以区分不通方法用于不同场景的调用。
NOW用于poll()、tryTransfer(E e)方法调用ASYNC用于offset()、put()、add()方法调用SYNC用于transfer()、take()方法调用TIMED用于poll(long timeout,TimeUnit unit)、tryTransfer(E e,long timeout,TimeUnit unit)方法调用
行为分析
1 | /* |
以上是主要我们要分析的行为,可以看见,出来 hasWaitingConsumer 和 getWaitingConsumerCount ,其他对队列操作元素的方法,都是通过xfer方法实现的。
先看 hasWaitingConsumer 和 getWaitingConsumerCount 。
1 | public boolean hasWaitingConsumer() { |
1 | public int getWaitingConsumerCount() { |
以上两个方法还是挺清晰的,主要是要注意一个地方,就是第一个未匹配节点的类型,决定了后边未匹配节点的类型。
接下来看看 xfer 方法。
1 | private E xfer(E e, boolean haveData, int how, long nanos) { |
结合xfer注释,对照着前边的几个操作队列元素的方法,多理解几遍,效果更佳。
总结
- 内部采用了Dual Stack With Slack的结构,slack根据实践数据采用了slack=2
- 操作队列的元素的各个方法通过xfer方法实现,具体是根据不同的how参数来区分不同场景
- 对于一个data节点,匹配过程体现在item上就是:non-null -> null,反过来,对于一个request节点,匹配过程就是:null->non null。
- 一个可阻塞的节点入队时,如果队列中有等待可匹配的节点,则匹配并移除该节点,否则,入队自旋等待或阻塞等待直至匹配成功或唤醒。